利用预训练语言模型拓展实体集合
今天介绍一个小众的 Task, 实体集合拓展(Entity set expansion).
Empower Entity Set Expansion via Language Model Probing. ACL 2020.
Yunyi Zhang, Jiaming Shen, Jingbo Shang, Jiawei Han
任务的目标是拓展原有的实体集合,向其中添加相同类别的实体,注意这里的实体类别一般不是传统的 7 大 NER 类别,更偏向 Fine-grained 的。 举个例子,原有集合{德州,杭州,青岛},可以拓展为{林芝,六盘水}之类的。
简单的话,我们用聚类 Contextual Embedding(类似于 Word Sense Induction 中的做法), 或者用 pair-wise loss 增强 Similarity 的计算可以给到一个结果。
但这样操作会有两个缺点:
- 单纯的相似度计算,容易拓展不准确的实体(非同级,反义词,High level 相似,但细粒度不同).
- 随着集合的拓展,容易出现语义偏移等误差累计问题.
如果能获得实体集合的类别名称,能减少歧义,促进对实体集合的理解。
本文从这个角度出发,通过两个 query 分别预测实体类别和实体, 试图更好的利用预训练模型中的语言知识。
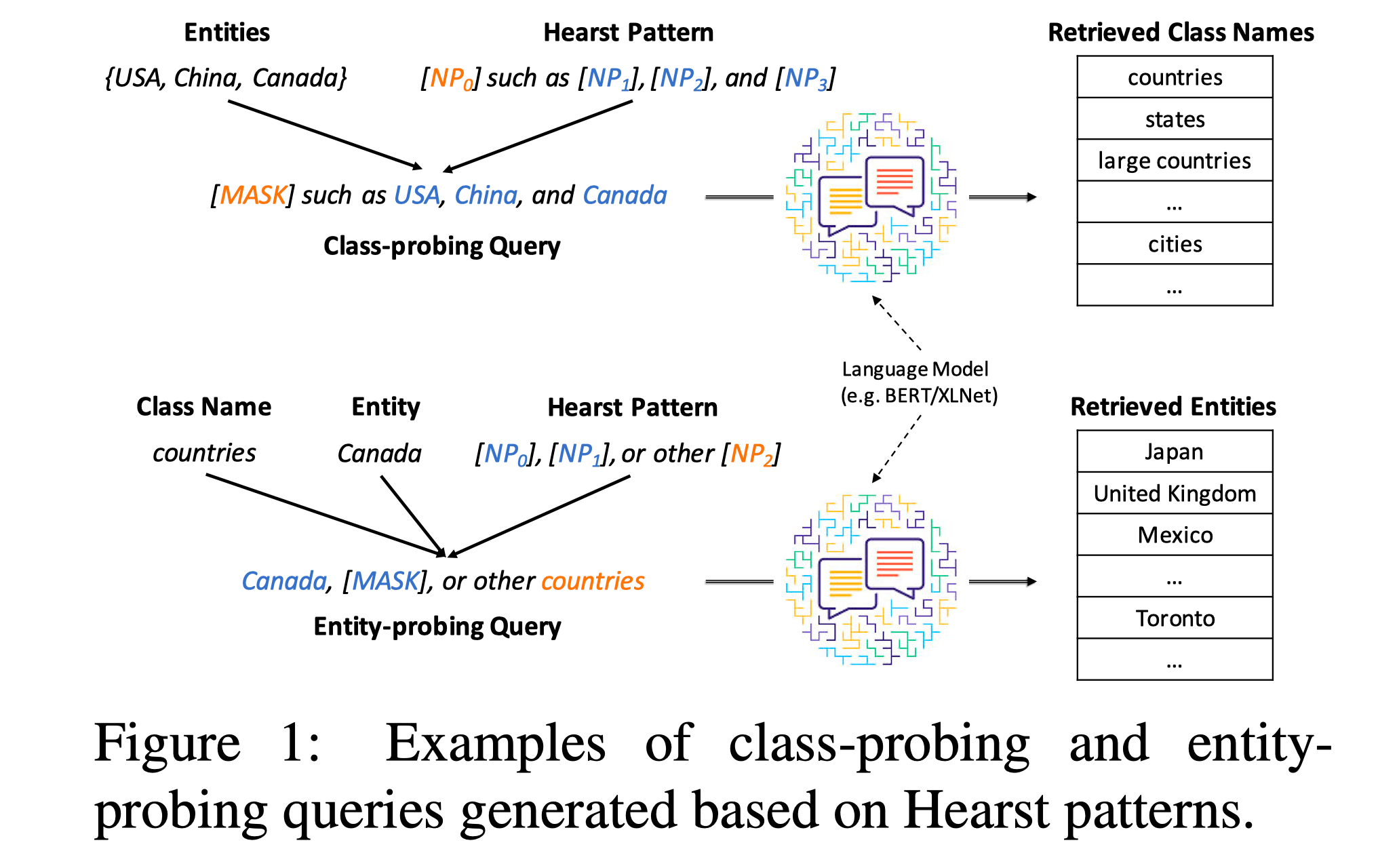
初看可能思路比较简单,只是做一个 MLM 的预测。 但如果只是这样,最多只是让生成的实体更符合生成的 class name,但很容易产生误差传递的问题, 并没解决语义偏移的问题。
文中使用了一些 tricks, 来试图解决以上问题,(体现在阅读观感上,就会觉得这个模型有点繁琐)。
Class-guided Entity Expansion
具体来说,这是一个三阶段的 pipeline 模型。
- 集合类名生成(class name generation).
- 集合名称排序(class name ranking).
- 集合指导下的实体选择(class-guided entity selection).
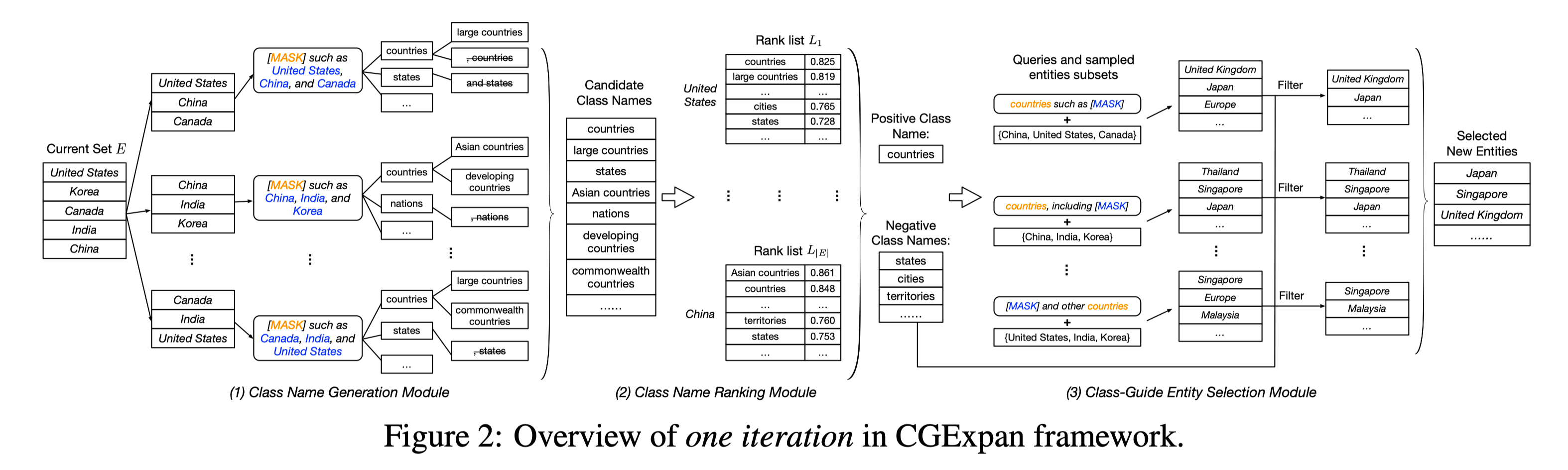
Class Name Generation
这一部分是三个阶段中最简单的一个,主体架构就是 MLM。
这个过程类似于一个已知特定的下位词,寻找通用的上位词这个过程。
使用 Hearst(1992)年提出的,六个 pattern 构建 query。
每次随机抽取三个实体组成一个 query。
这些 query 简短,主要起到的构建层次化语义,强化归纳类别信息的作用,例如Country such as China, Japan, South Korea.
- NPy such as NPa
- such NPy as NPa
- NPa or other NPy
- NPa and other NPy
- NPy, including NPa
- NPy, especially NPa
通过 Mask pattern 中 class name 部分,预测出最符合当前三个实体的 class name。
但这样操作也只能预测出 single token 的 class name, 适用性较差。
这边就采用一个迭代+beam search 的策略。依次向前填词。例如先预测出来country, 然后再去预测Asia country.
每轮选取 top-k 的候选集依次向前。
最大长度限制在 3,然后利用 pos tag 工具(nltk)来筛除非名词短语。
和很多 pipeline 模型一样,这个阶段的目标只是高 recall,通过多次 sample entity subset 来尽可能提高 recall。
Class Name Ranking
单纯的做上面的 MLM 任务,使用的只是 LM 学到的分布,不一定符合当前 Corpus.
在这个阶段,目标是筛选出来最佳 class name($c_p$) 和一些负样本($C_N$, 用于后面辅助选择 entity).
一个简单的想法,统计前面一个阶段每个 class name 出现的次数,作为排序的指标,但是容易更偏向短 token。
这边定义一个实体-类别相似度 M,其通过两个 Max 获取到最相关的共现关系。
$X_e$ 表示语料集中所有 entity 的 representation,$X_c$ 表示 Hearst pattern 用 MASK 遮掉实体词的 representation.
内层 Max 是寻找每一个 entity representation 最吻合的 query pattern,外层本质上是一个筛选 Top-k 的 contextual.
对于原始实体集合 E 中的每一个实体 $e_i$ 都获得一个 class ranking list $L_i$.
最后的 class score 用各个 ranking list 的排名倒数和,$s(c)=\sum_{i=1}^{|E|} \frac{1}{r_{c}^{i}}$.
通过这样操作放大不同排名 class name 之间的差距。
取 S(c)最大的作为正例$c_p$, 选取各个 ranking list 中排名都比$c_p$低的作为负样本$C_N$.
Class-guided Entity Selection
先用 AutoParse 从 raw text 的 Corpus 中抽取 entity 候选集。
然后定义 class-entity 匹配程度,从两个角度出发。
- Local score,
${score}_{i}^{l o c}=M^{k}\left(e_{i}, c_{p}\right)$ - Global score,
${score}_{i}^{g l b}=\frac{1}{\left|E_{s}\right|} \sum_{e \in E_{s}} \cos \left({v}_{e_{i}}, {v}_{e}\right)$
第一个式子,使用 Class Name Ranking 中定义的 M,来获取 Corpus 中和 class name 中最吻合的 k 个位置作为其表示。 这边称之为 local,感觉想表达这种 score 只蕴含相似度头部部分,是一种局部的评价。
第二个式子,先 mean pooling Corpus 中所有该实体的 contextual representation,然后与 origin 实体集合中的实体做 cos 相似度。
注意,我们计算时用的是从 E 中随机抽取出来的子集$E_S\in E$,以期降低 noise 的作用,有一点 boosting 的感觉。
这种算是追求 contextual-free 的操作。
最后的 score 值,由两者的乘积方根表示。
到这里我们实际上是可以做一个 Entity Ranking List(R)输出, 但是好像还没用到 negative class name.
回想一下,我们前面分析的会出现的问题,第一个是 ambiguous 这个试图用 class name,还有后面的一些 score 计算方式来解决;第二个语义偏移,我们好像还没办法解决。
这边就用一个回溯的思想,把 entity $e_i$ 加到 E 中再做一次 Class Name Ranking.
讲道理如果没有发生语义偏移的话,那应该$c_p$还是第一,$c_p$ 应该还是要比所有 negative sample 排名要高。
在这边就用一个指示函数来做这件事,当然用指示函数就相对于去截断,是一个 filter 兜底的过程。
然后,重复抽取子集$E_S$T 次,构建出 T 个 Entity Ranking List.
这边用两种模式,汇集这 T 次的结果。
- 排名的倒数.
$s^{t}\left(e_{i}\right)=\frac{1}{r_{i}^{t}}$ - 相对 score.
实验解决显示,方案 1 效果会更好点。
值的注意的是这种模式还提供了删除前期 expanded entity 的可能。
重复上述 pipeline 直到 set 达到预定大小(50) 或者连续三次 set 不变.
Experiments
在 Wiki 和 APR 这两个数据集上进行测试。 Wiki 是 Wikipedia Corpus 的子集,APR 则是 15 年的一个新闻数据集。 因为 BERT 在 Wikipedia 上 trained 过,在 Wiki 上测试能够反映出来这个方法能不能把 pre-trained 学到的知识展示出来。
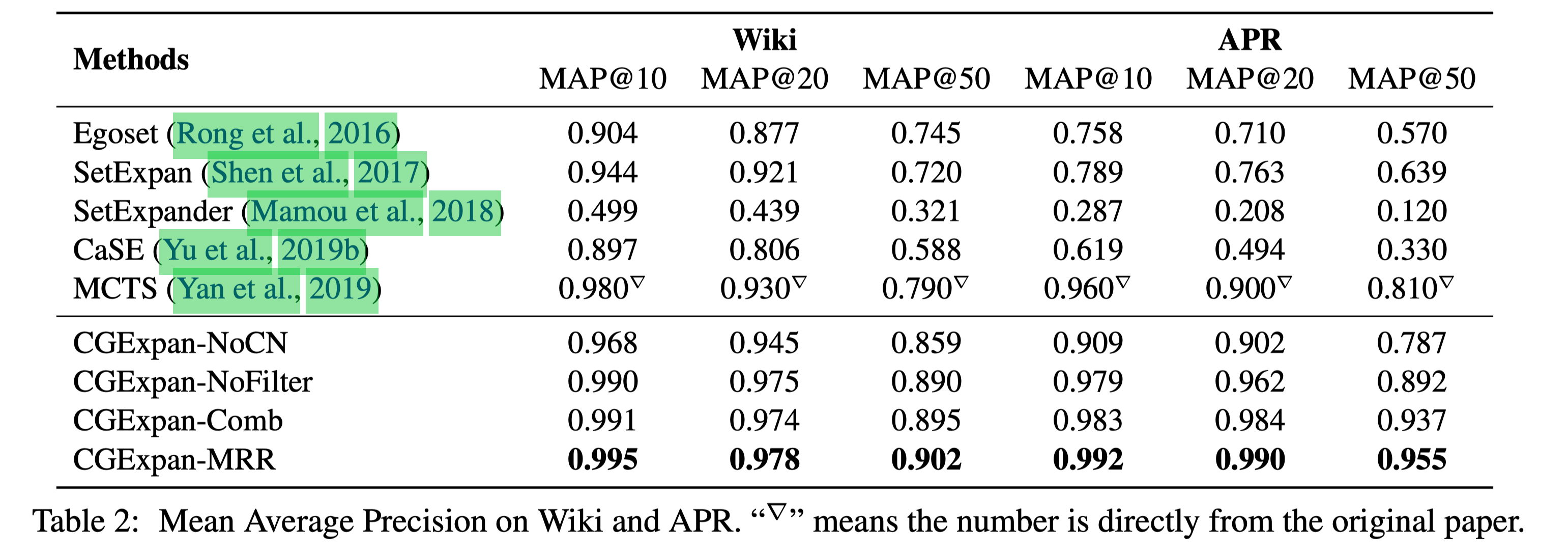
实验结果相较于之前的 baselines 有显著提升,尤其是在 MAP@50 中。
Ablation experiments 中,NoCN 是去掉 Class name 模块直接计算 score,相对于一个只用 BERT representation 的方案。 通过对比这个强 baseline,可以发现加上 class name 对于整体语义理解很有帮助。
NoFilter 在 Wiki 上差异不大,在 APR 上就比较大了,可能是 BERT 已经能很好控制 Wikipedia 语料中语义的情况。
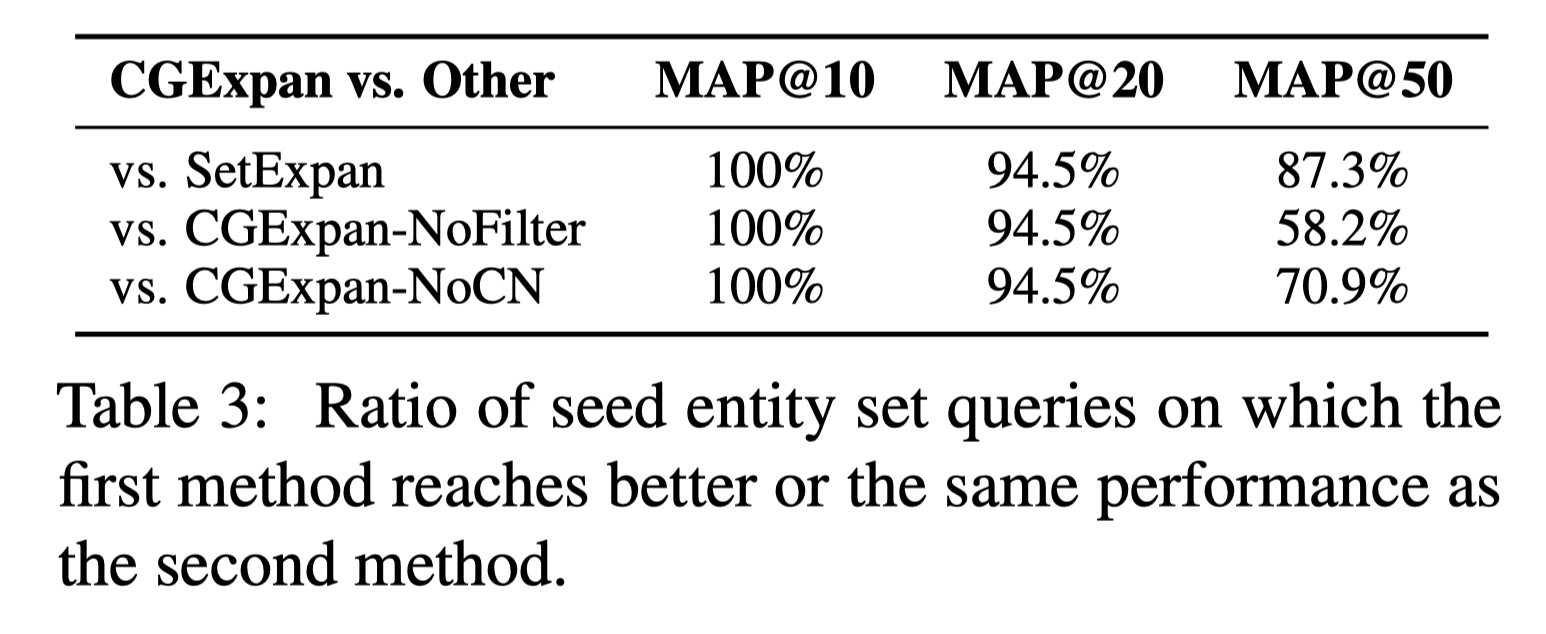
这张表可能要结合 case study 才能分析,对 55 个 entity set 进行分析,MAP@10 比较稳定,到还好解释,对于 SetExpan 应该属于全面优于的佐证,对于其他 ablation 模式,更偏向于对于 Top 靠前差异不大。 但对于 MAP@20 比较稳定就有些迷惑,大概率是微笑的偏差造成百分比的放大。 这个结果也和前面的 result 比较吻合,对于 NoFilter 提升的有限(当然感觉主要还是 Wiki 的原因,Wiki 占了 40/55)。
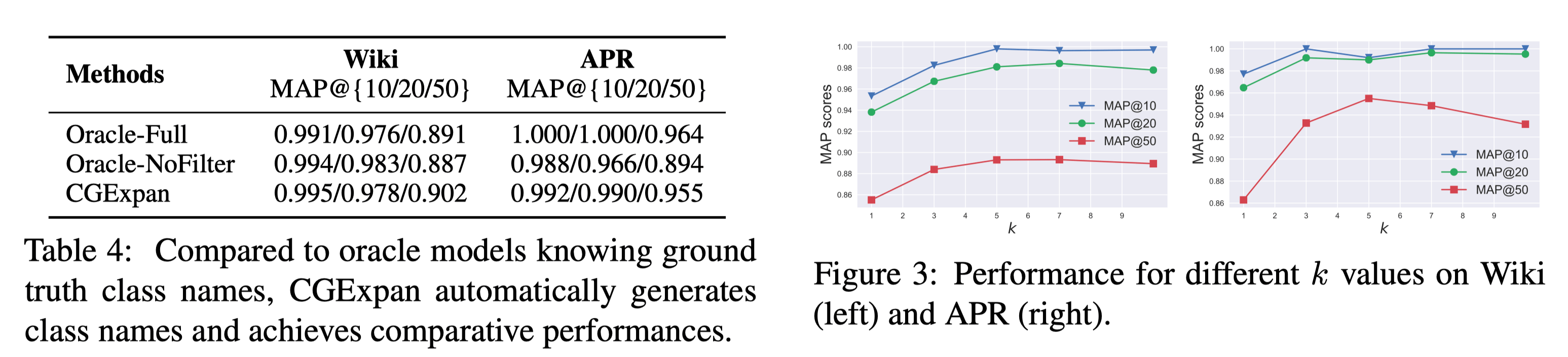
当提供 ground truth class name 时可以发现在 APR 上提升明显,在 Wiki 上差异不大,反而是 CGExpan 学出来的 class name 效果更好(可能更少的噪声)
调节 M 中的 k(top-k co-occurrence), 当 k>5 的时候提升不明显了,所以实验中设定 k=5.
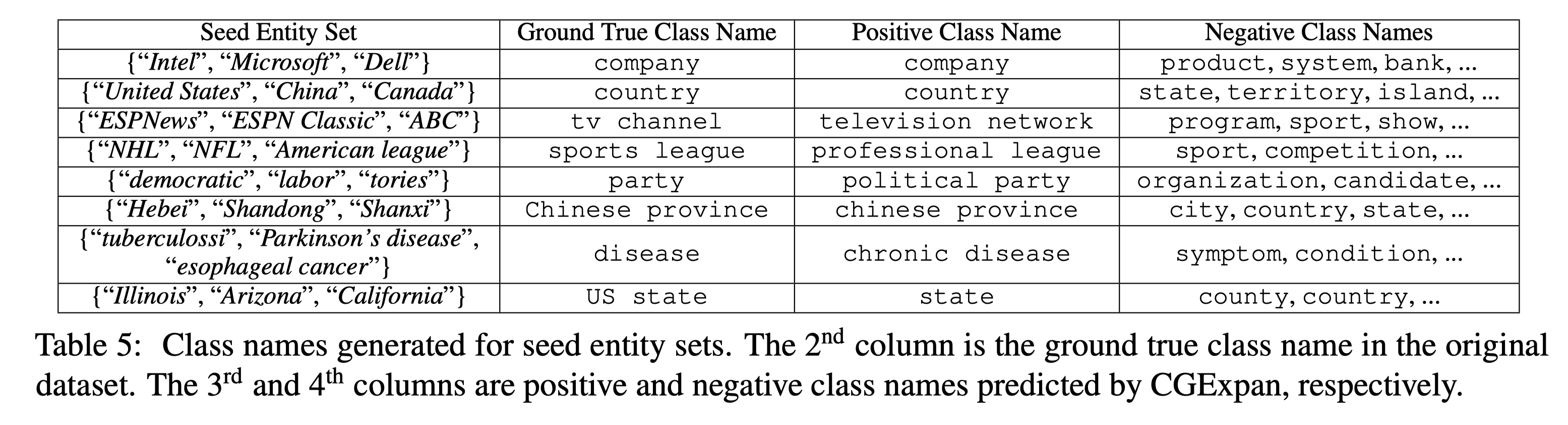
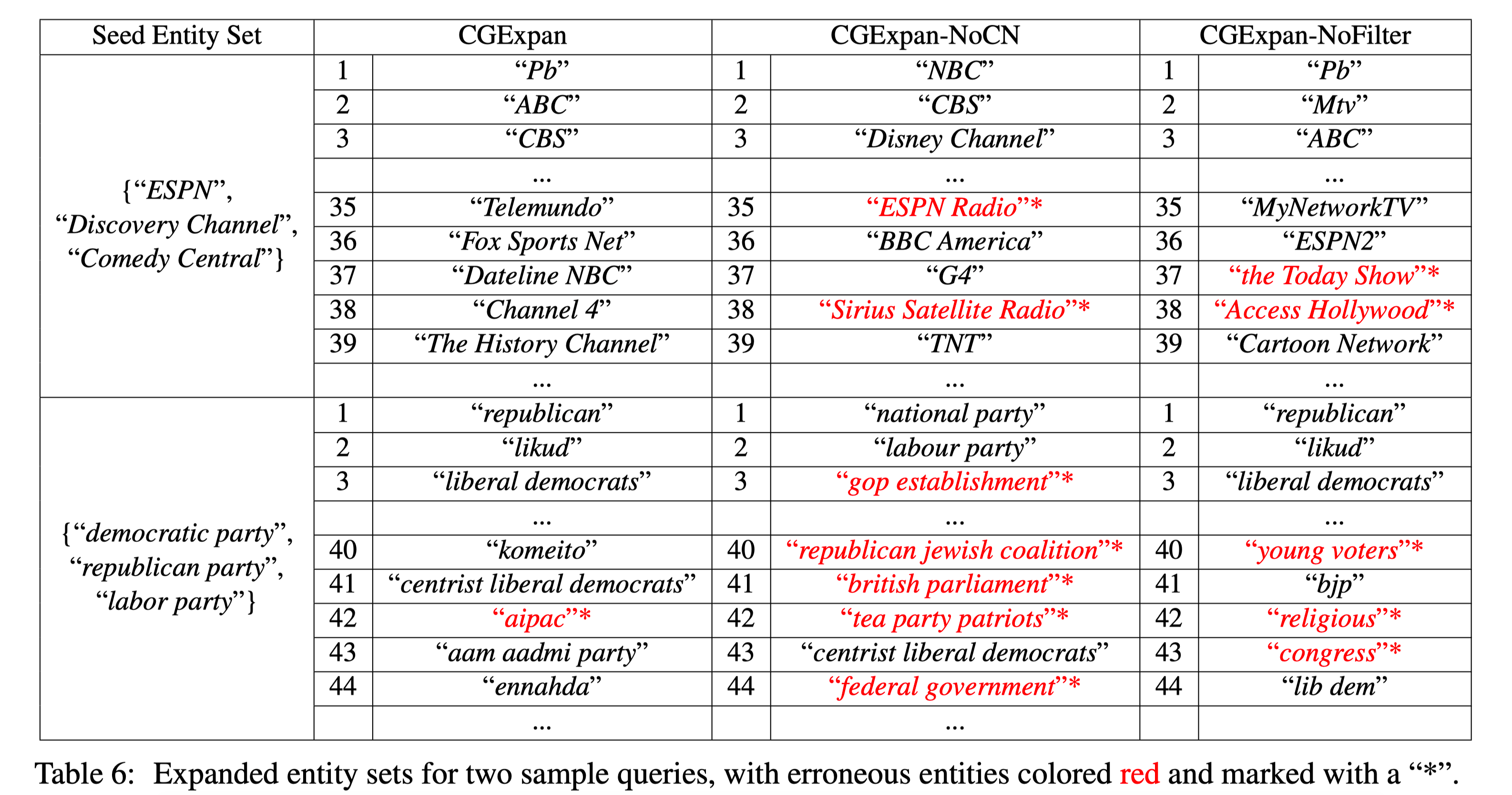
Case study 中可以看见 negative class name 很高质量,能够分离特别相近的语义。
Discuss
- CGExpan 是一种从预训练 LMs 中提取信息的一种模式。
- 不需要 train,也使得 pipeline 的误差传递会比较少。
- class name, filter 策略效果还是比较明显的。
- 但目前 entity set 只有 55 个,样本量整体偏小,另外 wiki 被 BERT 训过,泛化性需要进一步考证。
- 不过这套模式,扩展性比较强,可以用于主题扩展,商品扩展等。作者也写了一下 future work,比如说扩展抽象概念,构建语义族。
- 如果有 pair-wise 的对比实验就更好了
水平有限, 欢迎讨论.