Transformer结构中获得相对位置信息的探究
“原来你还关注了这个专栏” “这个博主还能敲键盘呀”
没错,时隔半年,终于终于要更新了 🙊 (主要是我太咸鱼了
这次主要讨论一下如何增强 Transformer 结构对获取相对位置信息的能力(即 Relative Position Embedding in Transformer Architecture)。
Background
事实上,Transformer 是一种建立在 RNN 之上的结构,其主要目的是在提升并行能力的基础上保留获取长程依赖的能力。 MultiHeadAtt 获取多种 token 与 token 之间的关联度,FFN 通过一个超高纬的空间来保存 memory。
通过各种 Mask(Regressive 之类的) Transformer 可以做到不泄露信息情况下的并行。 在实际实验中,速度可能会比 LSTM 还快。
为了补救,Transformer 在输入的 Word Embedding 之上,直接叠加了位置编码(可以是 trainable 的,但实验结果显示 train 不 train 效果差不多,在 Vanilla Transformer 中位置编码是 fixed 的)。
但事实上这种 Position Encoder 或者叫做 Position Embedding 在 word embedding 上直接叠加能带来的只有位置的绝对信息
\begin{equation} \begin{aligned} \mathbf{A}_{i, j}^{\mathrm{abs}} &=\underbrace{\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{E}_{x_{j}}}_{(a)}+\underbrace{\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{U}_{j}}_{(b)} \\ &+\underbrace{\mathbf{U}_{i}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{E}_{x_{j}}}_{(c)}+\underbrace{\mathbf{U}_{i}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{U}_{j}}_{(d)} . \end{aligned} \end{equation}
(a) 与位置无关,(b),(c) 只有绝对位置信息, 而(d)项实际上也不含有相对位置信息。
回顾 PE 的定义,由一组 $sin$,$cos$ 组成,为了构造一个 d 维的位置编码(与 word embed 相同维度,分母的次方逐渐增大)
\begin{equation} \begin{aligned} P E_{t, 2 i} &=\sin \left(t / 10000^{2 i / d}\right) \\ P E_{t, 2 i+1} &=\cos \left(t / 10000^{2 i / d}\right) \end{aligned} \end{equation}
于是可证$PE^T_{t+k}PE_t$只与相对距离 t 有关。
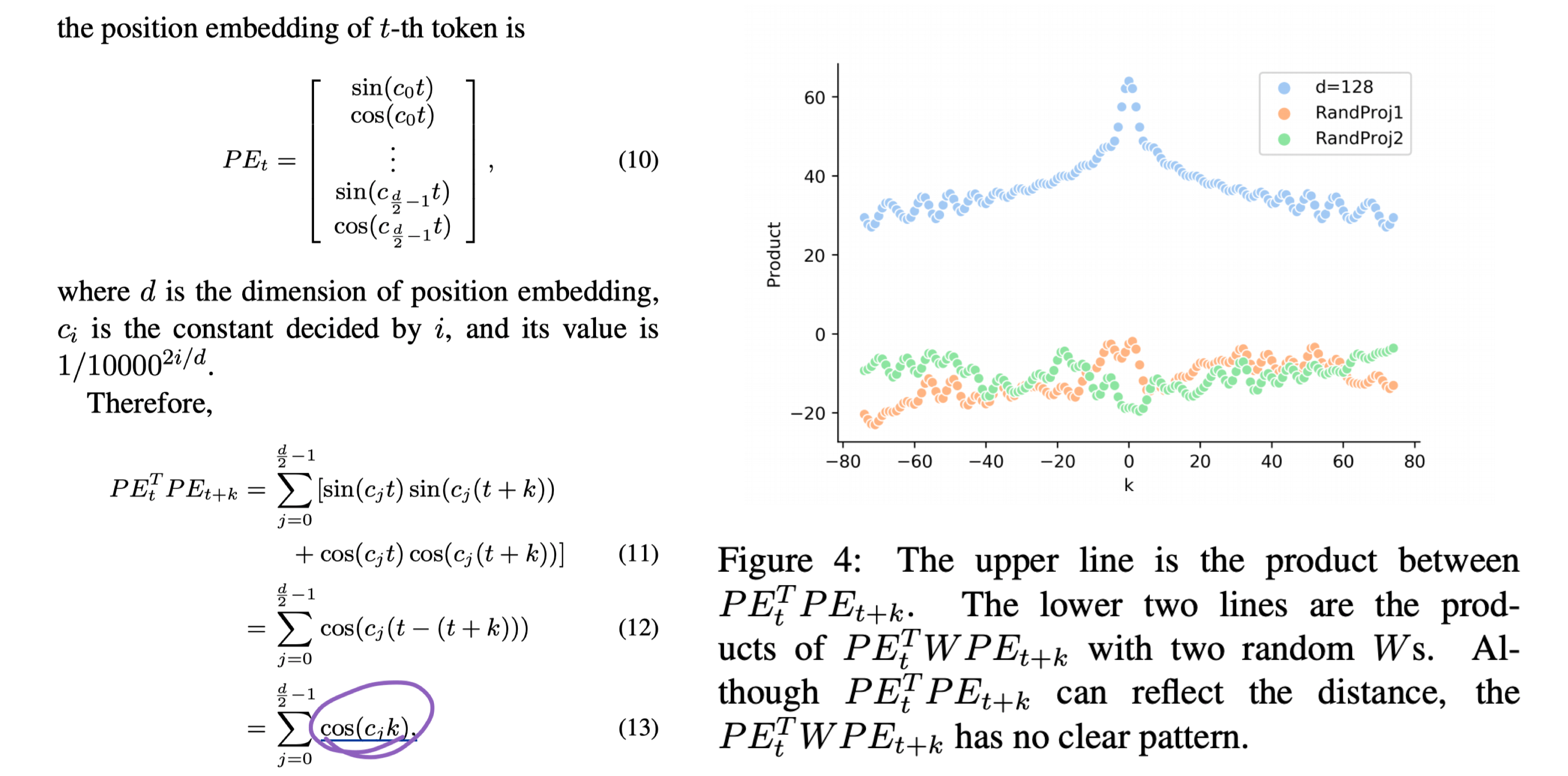
但实际上在$PE^T_{t+k}$与$PE_t$之间还有两个线性 W 系数的乘积(可等效于一个线性系数)。
由随机初始化 W 之后的 d 项与相对距离 k 之间的关系图可知,W 项的扰动使得原有的 Attention 失去了相对位置之间的信息。
这就使得 Transformer 结构在一些特别依赖句内 token 间相对位置关系的任务效果提升没有那么大。
本文就这个问题,介绍四篇工作。
- NAACL 2018. Self-Attention with Relative Position Representations.
- ACL 2019. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context.
- -. TENER: Adapting Transformer Encoder for Named Entity Recognition.
- ICLR 2020. Encoding word order in complex embeddings.
改变 Attention 计算项
既然是在 Attention bias 计算中丢失了相对位置信息,一个很 Naive 的想法就是在 Attention bias 计算时加回去。
Self-Attention with Relative Position Representations.
18 年的 NAACL(那就是 17 年底的工作),文章是一篇短文,Peter Shaw, Jakob Uszkoreit, Ashish Vaswani 看名字是发 Transformer 的那批人(想来其他人也不能在那么短时间有那么深的思考 🤔).
他们分别在 QK 乘积计算 Attention bias 的时候和 SoftMax 之后在 Value 后面两处地方加上了一个相对编码(两处参数不共享)。
\begin{equation} \begin{aligned} z_{i} &=\sum_{j=1}^{n} \alpha_{i j}\left(x_{j} W^{V}+a_{i j}^{V}\right) \\ e_{i j} &=\frac{x_{i} W^{Q}\left(x_{j} W^{K}+a_{i j}^{K}\right)^{T}}{\sqrt{d_{z}}} \end{aligned} \end{equation}
为了降低复杂度,在不同 head 之间共享了参数。
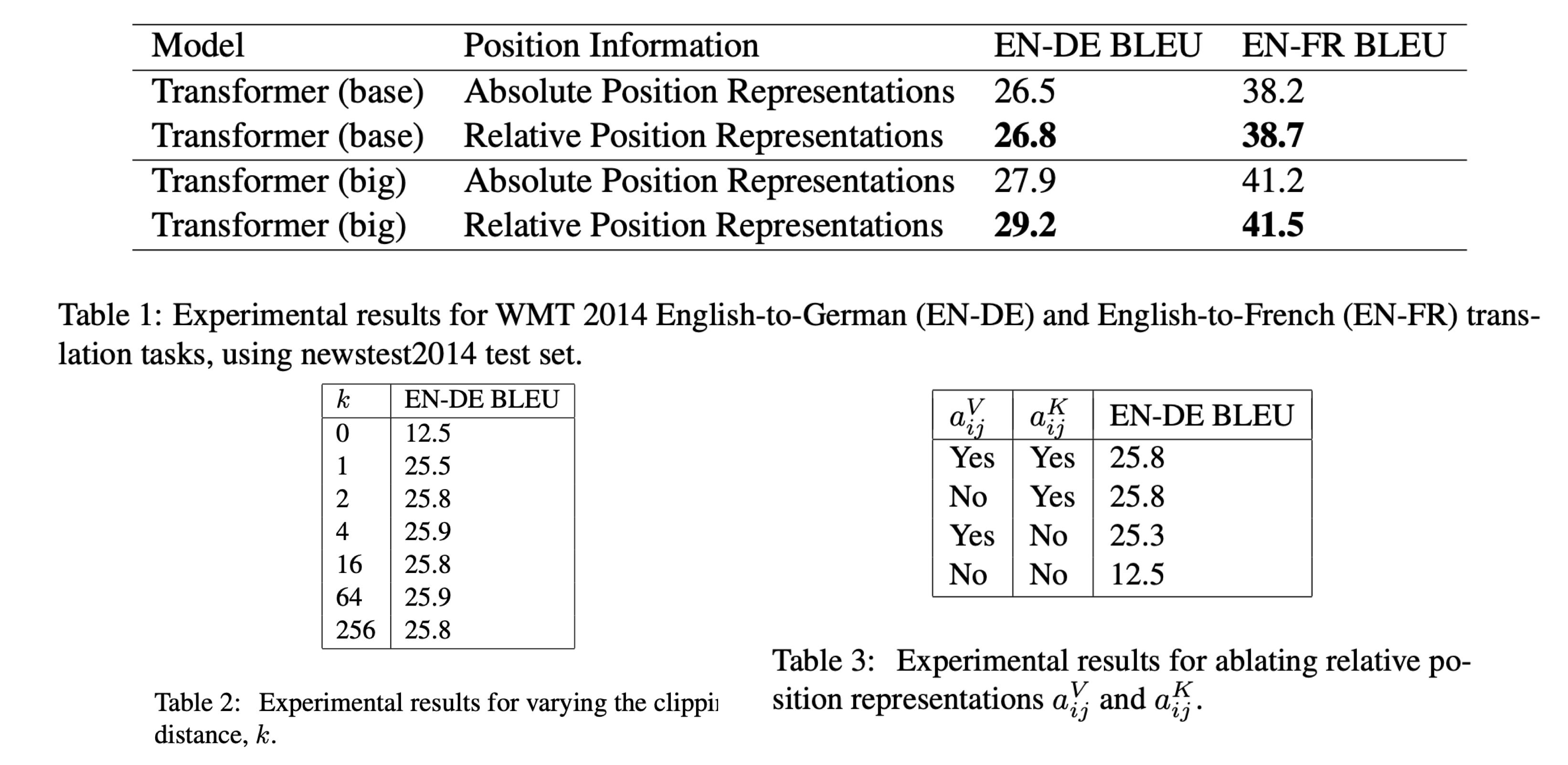
实验显示,在 WMT14 英德数据集上 base model BLEU 提升了 0.3, big model 提升了 1.3。 Ablation 实验中,改变最大位置距离 k,显示 k 从 0-4 增大的过程 performance 有明显的提升,之后再增大 k 提升不明显。 Attention bias 中的相对项提高更多的 performance, 而 SoftMax 之后再 Value 上加的那个相对项提升的性能略少。
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context.
Transformer-XL 的工作现在可以称之上开创性的了。
除却递归更新 blank 的过程,relative position embedding 也是论文的一大亮点.
可能作者在思考的过程中更多是在 recurrent 是 PE 重叠造成的偏移角度出发。
但实际上 relative 的改动对于模型获得句内细粒度层次的信息也是很有帮助的。
\begin{equation} \begin{aligned} \mathbf{A}_{i, j}^{\mathrm{rel}} &=\underbrace{\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k, E} \mathbf{E}_{x_{j}}}_{(a)}+\underbrace{\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k, R} \color{green}{\underline{\mathbf{R}}_{i-j}}_{(b)}} \\ &+\underbrace{\color{red}{u^{\top}} \mathbf{W}_{k, E} \mathbf{E}_{x_{j}}}_{(c)}+\underbrace{\color{red}{v^{\top}} \mathbf{W}_{k, R} \color{green}{\mathbf{R}_{i-j}}_{(d)}} \cdot \end{aligned} \end{equation}
与 NAACL18 那篇不同的地方,Transformer-XL 舍弃了在 SoftMax 之后再叠加 Rij。
另外把 Attention Bias 中,另外两项因为引入 PE 产生的表征绝对位置信息的两项替换成不包含位置信息的一维向量(这里专门为前面 recurrent 模式设计的,感觉如果不搭配 Transformer-XL 使用的话这个改动并不一定是最合适的)。
除此之外,为了避免相对引入的巨大计算量,利用类似 AES 中的 shift 操作可以把复杂度降到线性。

通过 Ablation 实验可以看出相对于 NAACL18 的改进能显著提升效果。
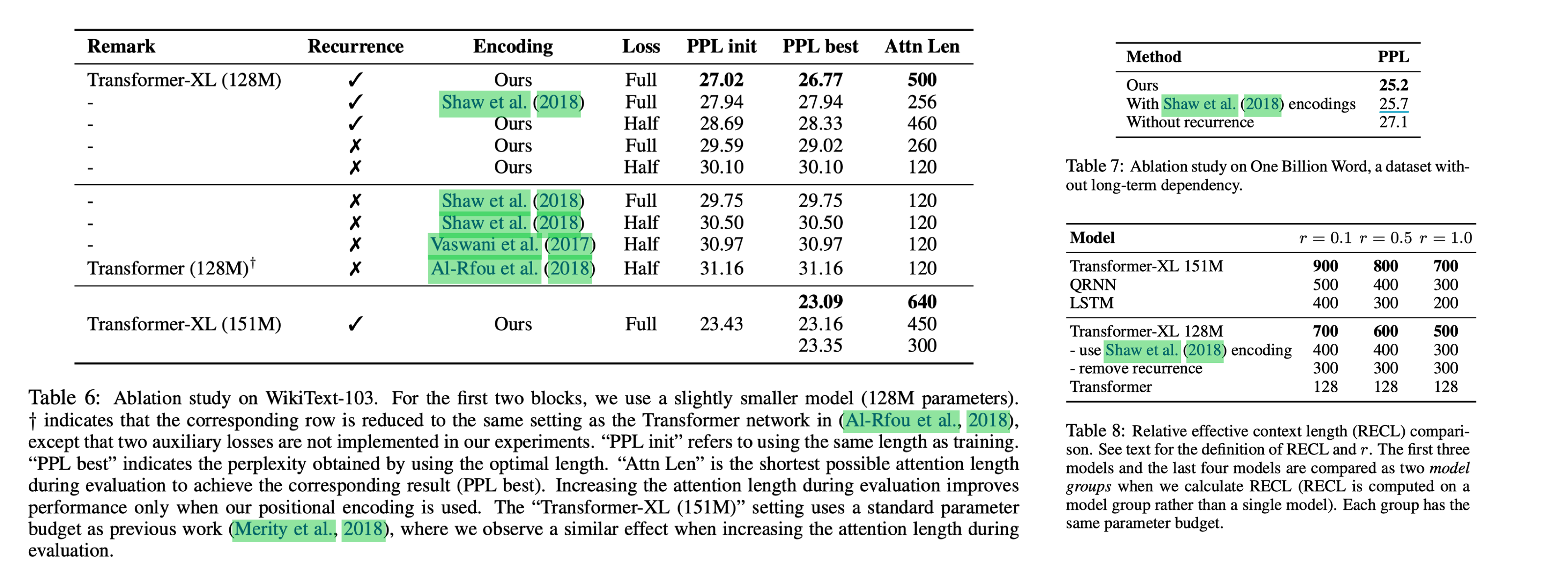
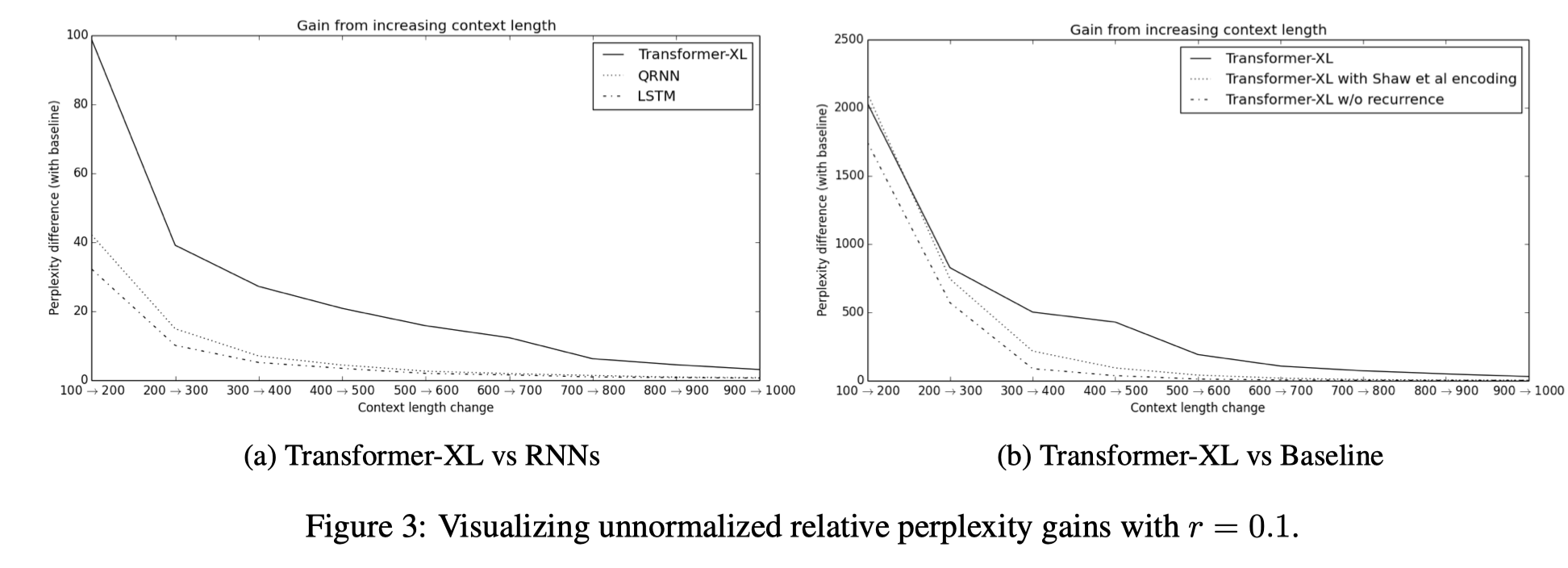
另外通过 RECL 实验也能看出 relative PE 对模型的长程能力有所帮助。 RECL 是一个逼近实验,通过测量上下文长度为 c + △,相对长度为 c 时最小 loss 的变化率。
当变化率低于一个阈值的时候就说明大于长度 c 的信息对模型 performance 提升帮助不大。
TENER: Adapting Transformer Encoder for Named Entity Recognition
这篇是复旦邱老师实验室的工作。
在 Relative PE 计算上的 InSight 不大,硬要说的话可能是减少了 Key 前面的线性项。
实验是在中文 NER 上做的一些测试,可能看出提升的不是特别明显,尤其是在 MSRA 上还是钰颖姐和 guoxin 的那篇效果好。
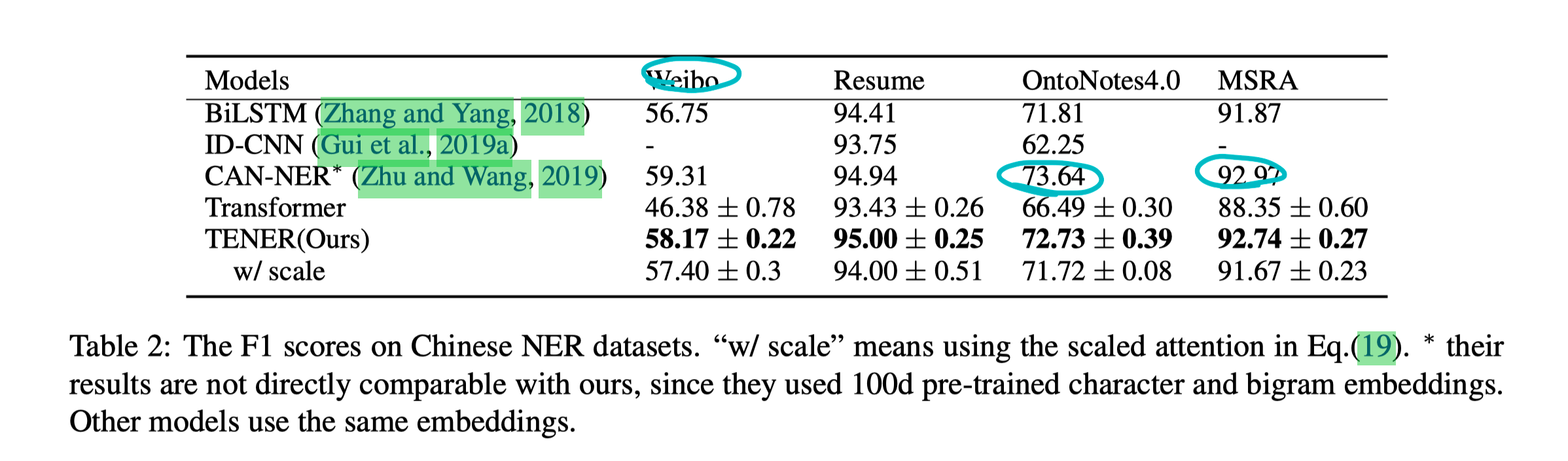
(感觉 NER topic 中 Relative PE 还是有些工作可以继续做下去的
Encoding word order in complex embeddings
除了上面一系列从 Attention bias 出发的角度,还有 dalao 从 PE 与 WE 结合方式角度出发做的工作。
从抽象层次看,前面的方法都是在补救因为(WE+PE)乘积项造成的丢失相对位置信息。
如果 WE 和 PE 的结合方式不是加性呢。
今年 ICLR 的有一篇工作就是从这个角度出发,将 WE 于 PE 组合分解成独立的连续函数。
这样在之后的 Attention Bias 计算时也不会丢失 Position 相对信息。
为了达成这个目的,就需要找到一种变换,使得对于任意位置 pos,都有$g(pos+n) = \text{Transform}_n(g(pos))$, 为了降低难度把标准降低成找到一种线性变换 Transform。
而我们的 Embed 除了上面的性质之外应该还是有界的。
这篇文章证明在满足上述条件下,Transform 的唯一解是复数域中的$g(pos)=z_{2} z_{1}^{pos}$, 且 z1 的幅值小于 1。
(这个证明也是有、简单,reviewer 的说法就是有、优美
根据欧拉公式,可以进一步对上述式子进行化简
\begin{equation} g(\text { pos })=z_{2} z_{1}^{\text {pos }}=r_{2} e^{i \theta_{2}}\left(r_{1} e^{i \theta_{1}}\right)^{\text {pos }}=r_{2} r_{1}^{\text {pos }} e^{i\left(\theta_{2}+\theta_{1} \text { pos }\right)} \end{equation}
为了偷懒,把 r1 设成 1, 而$e^{ix}$的幅值等于 1,就恒满足 r1 的限定。
于是,进一步化简为 $g(\mathrm{pos})=r e^{i(\omega \mathrm{pos}+\theta)}$
这就是标标准准的虚单位圆的形式,r 为半径,$\theta$为初始幅角,$\frac{\omega}{2\pi}$ 为频率,逆时针旋转。
这个式子又可以化成$f(j, \text { pos })=g_{w e}(j) \odot g_{p e}(j, \text { pos })$ WE 与 PE 的多项式乘积,其中两者所占系数取决于学习到的系数。
于是这相当于一个自适应的调节 WE 和 PE 占比的模式。
实际上我们只需要去学习幅值 r, 频率 w,初始幅角$\theta$ (会造成参数量略微增大)
可以看出 Vanilla Transformer 中的 PE 是上式的一种特殊形式。
为了适应 Embedding 拓展到复数域,RNN,LSTM, Transformer 的计算也应该要拓展到复数域.

实验部分做了 Text Classification, MT, LM 三个 task。
Text Classification 选了 4 个 sentiment analysis 数据集,一个主观客观分类,一个问题分类,共六个 benchmark。
Baseline 设置
- without PE;
- random PE and train;
- 三角 PE;
- r 由 pretrain 初始化,w 随机初始化
$(-\pi, \pi)$; - r 由 pretrain 初始化,w train;
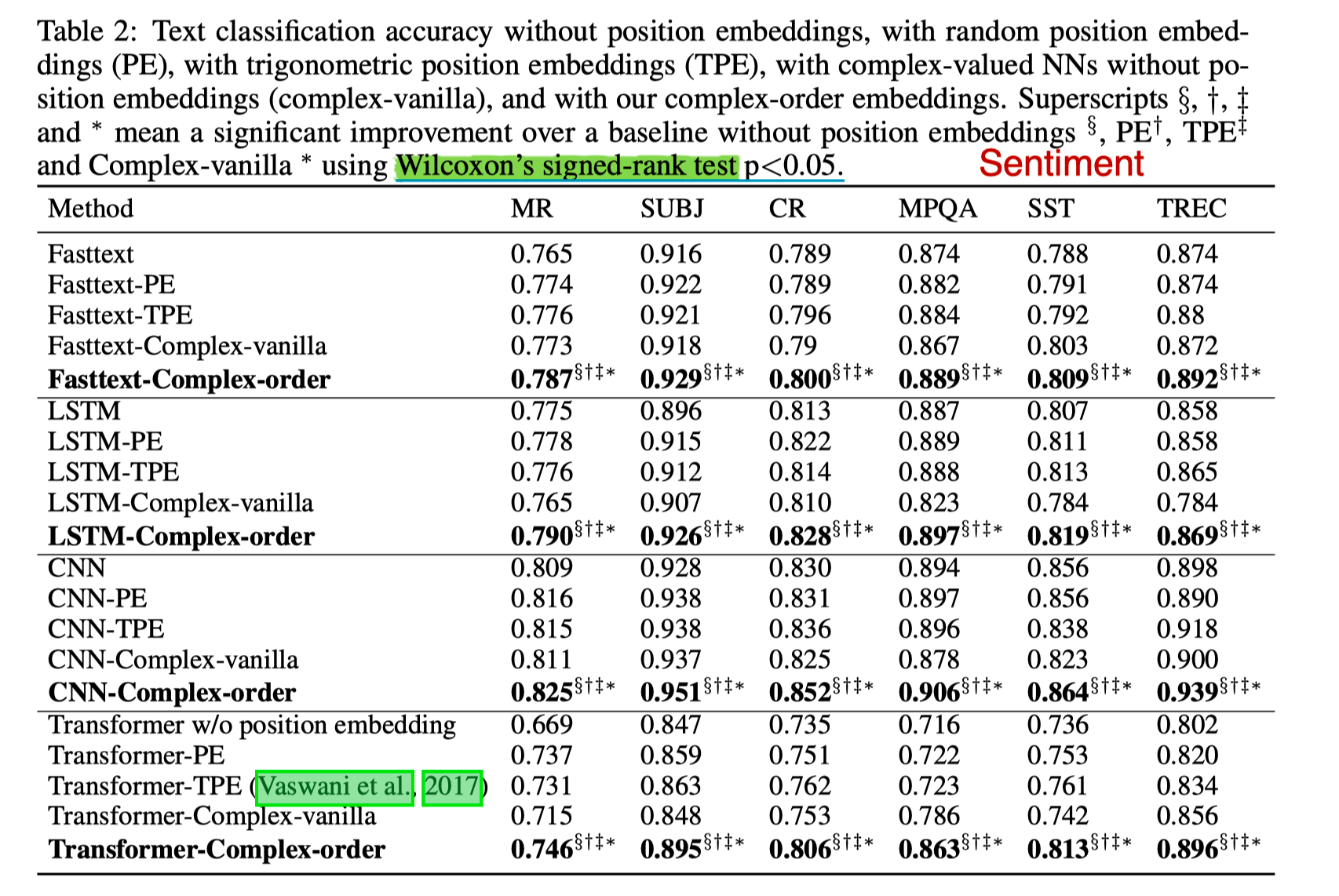
可以看出 performance 中三角 PE 与 Train PE 几乎没什么区别,所以 Vanilla Transformer 使用 Fix 的 PE 也是有一定道理的。
Complex order 对模型有一定提升,但不是特别多。
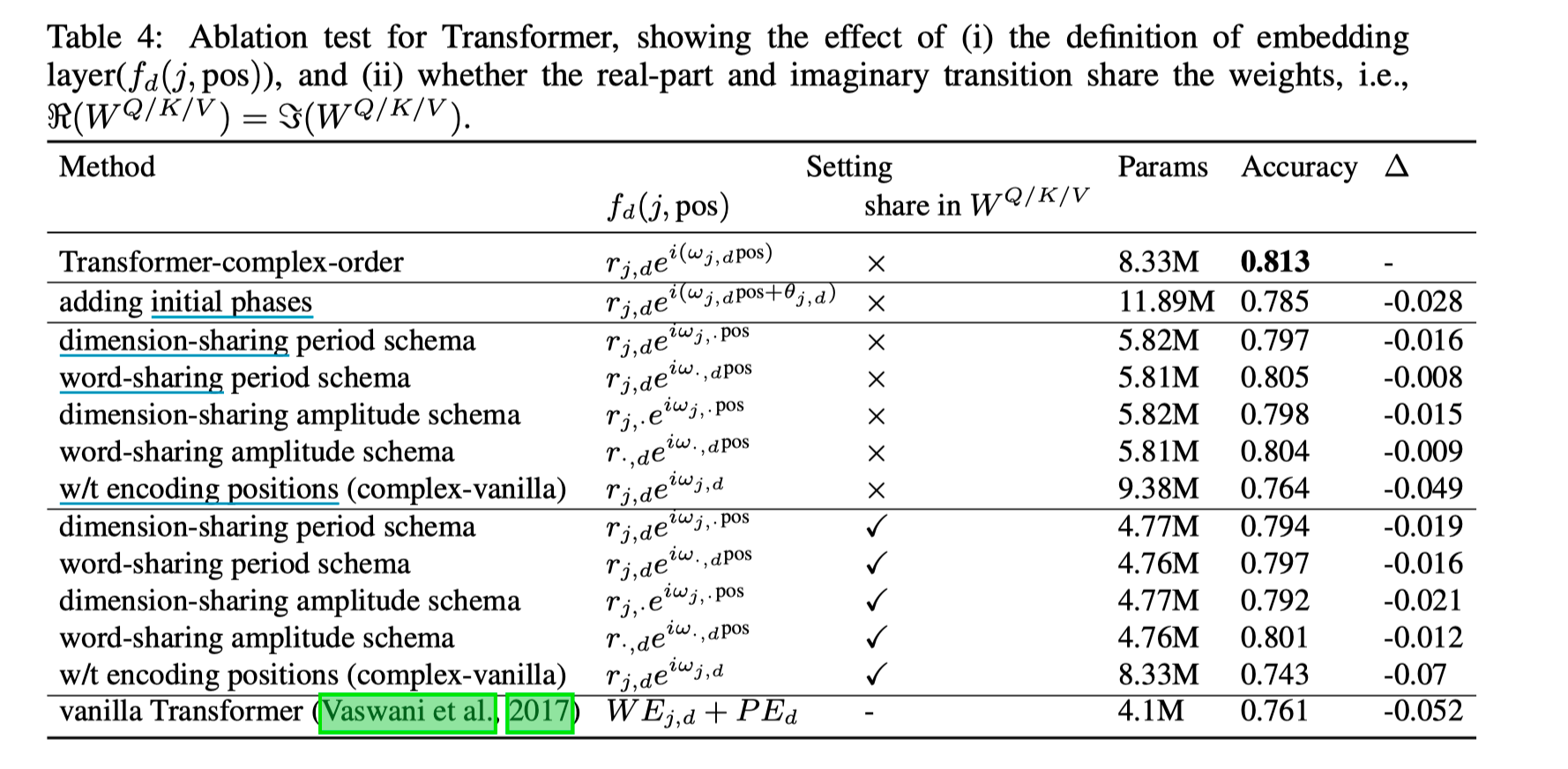
然后为了降低参数量,尝试了几种参数共享的组合。 (参数量的增大主要是因为 Transformer 结构扩充到复数域,参数量增大了一倍。但参数增大与 prefermance 关联度不大,共享 W 之后性能几乎不变。
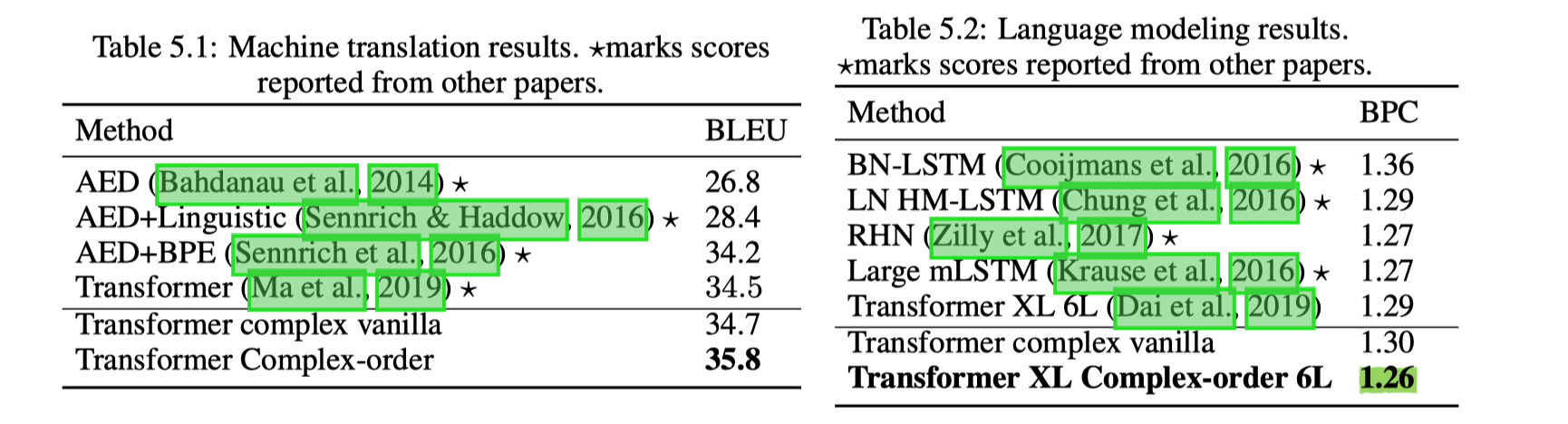
然后在 WMT16 英德和 text8 上测了在 MT 和 LM 上的性能,这两部分性能提升还是很明显的。尤其是 LM 在同等参数量下的对比试验。
(这篇的作者之前也发了几篇关于复数域上 NLP 的应用,之前模型的名字也很有意思 什么 CNM的 很真实
总的来说 自己的试验结果也显示 RPE 对 Transformer 或者说 Self-Attention 的性能还是很有影响的,还是可以 follow 一些工作的。